Building an artist recommender — Part I
The Problem
I‘m constantly listening to music. Most of the time, that‘s on Spotify — I‘m a big fan of their personalized Discover Weekly and Daily Mix. Although I appreciate the little amount of effort it now takes to "discover" new music, I want a bit more control over what type of music the recommender serves.
For the past 3 years I‘ve had the same top 10 songs — here‘s my list from 2018. Let‘s gloss over the fact that Shawn Mendes is #3… most of the songs here are what I use to focus while working. They‘re particularly effective at drowning out the noise around me, without having a heavy bass that would bother my coworkers.
Since I spend most of my waking hours focused working, Spotify mostly recommends artists that fit the non-lyrical, don‘t-break-my-flow genre. Oddly enough, this isn‘t really the type of music I want to discover… for fun.
Not only do I want to have a say in the type of music that I‘m being recommended, but I also want some control over the novelty of the recommendation. Occasionally, I have the time to dedicate an afternoon to listening to an unknown artist‘s entire discography (and later, drop this obscure music reference at a party 😎). Otherwise, I want to listen to artists who have a significant following but I‘m not familiar with. In a way, I want to turn the dials of the recommender to fit my mood.
Since I couldn‘t find a similar product on Spotify — and I desperately need more party tricks — I set out to build it myself. Early on, I knew a few things to be true:
- I don‘t want to risk handling user credentials, so it has to use only publicly-available data.
- It can‘t take ages to query, so I‘ll have to store every artist‘s top recommendations on [insert preferred cloud provider here].
- It needs a user-friendly interface, and maybe some cools visualizations.
Now to the crux
How would I determine what artists to recommend?
Well, I would first need a sense of the user‘s tastes. Maybe not everyone thinks Shawn Mendes is the next Justin Timberlake — everyone likes J.T. though. I‘ll use the user‘s most common artists across their public playlists as a proxy for their taste. Based on those artists, I can recommend new + similar artists.
New to the user
Most sensible playlists are curated around a theme and have similar songs and artists. If artists often show up in many playlists together, I can assume they are somewhat similar. My best bet is to analyze a ton of public playlists on Spotify — the more the merrier. I‘ll use this same approach to assign a novelty rank to an artist. By ranking artists based on how well connected they are, I can assume the top X% are popular artists.
Similar artists
One way I could approach this is by counting the times any pair of artists show up in the same playlists together. Since we're only looking at public data, our best bet is to analyze a ton of public playlists on Spotify.
By ranking artists based on how well connected they are, I can filter out the top X% so I don't recommend people well known artists.
The Data
I‘ll start out on a small set of data, and worry about scaling it later. I‘m going to limit the pool of playlists to all those created by the Spotify user account. Given that these are professionally curated by Spotify editors, and they get paid for this, I expect a high level of quality and consistency.
Using Spotify‘s playlist API, I can pull all the playlists I need from the US market. I chose to use Spotify's client credential flow to get a token.
# client_credentials_flow.py
def create_token(client_path, secret_path):
client = open(client_path).read().strip()
secret = open(secret_path).read().strip()
url = "https://accounts.spotify.com/api/token"
data = { 'grant_type': 'client_credentials' }
r = requests.post(url, data=data, auth=(client, secret)).json()
print("this access token will expire in {0} minutes".format(r["expires_in"] / 60.0))
token = r['access_token']
return token
You can check out the actual code on GitHub, but here's the simplified version of an API query.
#search.py
from collections import defaultdict
import requests
import client_credentials_flow # the one I wrote above
# we'll store our data in these dictionaries
nodes = defaultdict(dict)
edges = defaultdict(set)
user = "your-spotify-id" # the one that show's up in your playlist urls
path_to_client = "/the/path/to/client"
path_to_secret = "/the/path/to/secret"
token = client_credentials_flow.create_token(path_to_client, path_to_secret)
session = requests.Session()
headers = { "Authorization": "Bearer {0}".format(token) }
href = "https://api.spotify.com/v1/users/{0}/playlists?market=us&limit=50".format(user) # focus on the US market
request = session.get(href, headers=headers).json() # send request to spotify api
The request variable holds up to 50 public playlists for our user. Each of those playlists then has a reference to all of the tracks, which contain some of the artist information that we're after. I‘ll store every playlist + artist combination to use later.
while "items" in request and loop:
loop = True
# loop through all playlists
for playlist in request["items"]:
pid = playlist["id"]
# add playlist to nodes
nodes[pid] = { "node_id": pid, "name": playlist["name"], "type": "playlist" }
# get all tracks from this playlist
tracks = session.get(playlist["tracks"]["href"], headers=headers).json()
# pull tracks to see artists (there can be multiple)
if "items" in tracks:
for item in tracks["items"]:
for artist in item["track"]["artists"]:
aid = artist["id"]
nodes[aid] = { "node_id": aid, "name": artist["name"], "type": "artist" }
edges[pid].update([aid])
# move on to other playlists
if request["next"]:
request = session.get(request["next"], headers=headers).json()
else:
loop = False
At this point,I know which artists are connected to which playlists. Here's a visual using my own public playlists. Click on a playlist 🙌
- For each of my playlists, you can see the first 10 artists that they contain.
- For each artist within those playlists, you can see up to 10 other artists they‘re connected to (through playlists).
- The number in parentheses is the number of playlists these artists have in common (from my user data)..
With this information we can build a network graph between artists. The code looks something like this:
# search.py
def artist_graph(self):
artist_edges = collections.defaultdict(dict)
for pid in self.edges:
artist_set = self.edges[pid]
for combo in itertools.combinations(artist_set, 2):
self.nodes[combo[0]]["artists_connections"] += 1
self.nodes[combo[1]]["artists_connections"] += 1
if not (combo in artist_edges.keys()):
artist_edges[combo] = { "num_playlists": 1 }
self.nodes[combo[0]]["artists_degree"] += 1
self.nodes[combo[1]]["artists_degree"] += 1
else:
artist_edges[combo]["num_playlists"] += 1
result = []
columns = ["this_index", "other_index", "degree", "connections", "weight", "num_playlists"]
for combo in artist_edges:
in_id = combo[0]
out_id = combo[1]
np = artist_edges[combo]["num_playlists"] * 1.0
out_w = np / self.nodes[out_id]["artists_connections"]
in_w = np / self.nodes[in_id]["artists_connections"]
result.append(
[
self.nodes[in_id]["index"],
self.nodes[out_id]["index"],
self.nodes[in_id]["artists_degree"],
self.nodes[in_id]["artists_connections"],
in_w,
np
])
result.append(
[
self.nodes[out_id]["index"],
self.nodes[in_id]["index"],
self.nodes[out_id]["artists_degree"],
self.nodes[out_id]["artists_connections"],
out_w,
np
])
return pd.DataFrame(result, columns=columns)
Now I can pull down the same data for the Spotify user! I‘ll use this to build out the recommender. As of the date of this post, this is the composition of the Spotify public playlists (in the US market) — or at least what I could pull using their API:
- 1,469 playlists
- 30,300 artists
- 76,508 playlist to artist combinations
- 5,165,957 artist to artist connections (by way of playlists)
Which artists show up in most playlists?
| name | playlist_count | degree | connections |
|---|---|---|---|
| Drake | 100 | 2,455 | 5,778 |
| Khalid | 99 | 3,151 | 7,772 |
| Beyoncé | 96 | 2,398 | 5,731 |
| Rihanna | 93 | 2,350 | 5,382 |
| Ariana Grande | 92 | 2,178 | 5,940 |
| Nicki Minaj | 91 | 2,278 | 5,158 |
| Sam Smith | 85 | 2,540 | 5,637 |
| Taylor Swift | 82 | 2,311 | 5,535 |
| Lady Gaga | 81 | 2,092 | 4,613 |
| Calvin Harris | 79 | 2,628 | 5,679 |
| Kanye West | 77 | 1,773 | 4,256 |
| Ed Sheeran | 75 | 2,363 | 4,804 |
| John Mayer | 75 | 2,608 | 4,884 |
| Marshmello | 73 | 2,763 | 6,104 |
| Ellie Goulding | 72 | 2,131 | 5,403 |
| JAY Z | 71 | 1,775 | 3,844 |
| The Weeknd | 71 | 1,896 | 4,370 |
| Post Malone | 69 | 2,123 | 5,065 |
| Avicii | 69 | 2,168 | 5,093 |
| The Chainsmokers | 66 | 2,039 | 5,166 |
This tells us that Drake shows up in 100 of the 1,469 Spotify playlists (~7%), he's connected to 2,455 unique artists (i.e. degree), and has a total of 5,778 connections. To clarify, if Drake is in 20 playlists with Beyoncé, that is 20 connections but 1 single (-lady) degree.
There is something you need to know about the music industry: The 1% phenomenon is real. A small number of artists account for a majority of the connections. I ranked each artist based on the number of playlists they show up in. Take a look at how quickly the number of playlists per artist drops, as their rank decreases.
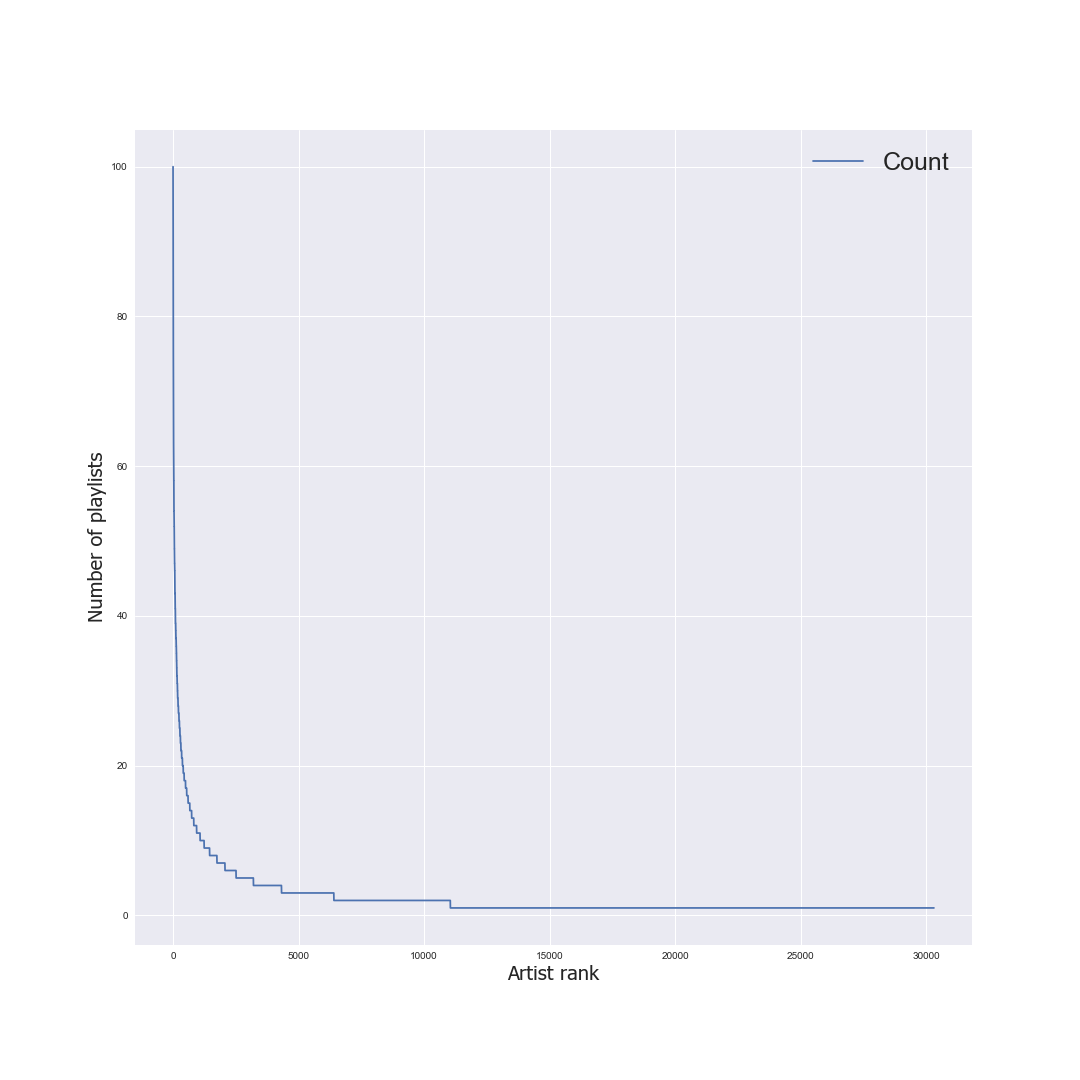
As you can see, out of 30K artists, 20K only show up in 1 playlist. This creates a bit of a problem; I want to recommend artists that are relatively unknown, but similar enough to artists that the user listens to. I can‘t consider an artist similar to another artist if they only show up in 1 playlist together. This will be a problem until I pull more playlists, so for now I‘m comfortable with recommending artists that are in the top ⅓. Scaling will be the topic of a future post.
The Model
I have enough data to start making recommendations, I need to give artists a novelty score. Remember, we want to give the user control of the novelty of a recommendation. My initial approach was to treat the artist-to-artist graph as an undirected weighted acyclic graph and ran PageRank. Let me break this piece down:- Undirected - there's no implicit direction between two artists who show up in a playlist together (i.e. I don‘t care about the song order).
- Weighted - we care if The Killers and Vampire Weekend show up in 20 playlists together vs 2 (i.e. the connections metric).
- Acyclic - we won't recommend you Bombay Bicycle Club if you listen to Bombay Bicycle Club
Turns out that the output of PageRank for an undirected graph converges to the centrality measure being used when calculating the transition matrix — intuitively obvious to the most casual observer. This fact simplifies the process significantly, and now I can simply rank the artists based on their connections.
The Recommendations
I‘m a big fan of Tom Misch — he‘s somehow able to find the perfect blend of Hip Hop and Jazz, and embed it into the smoothest guitar licks. Turns out, he‘s also the artist that shows up in most of my playlists. Knowing this, the recommender will try to serve me similar artists to Tom Misch.
738 — The number of total artists that show up in the 15 Spotify playlists that feature Mr. Misch.
17 — Number of artists that show up in more than 1 playlists with Tom, my guy.
10 — Artists left over when it cross-references my public playlists.
Here‘s that list of 10, showing the artist name, the number of playlists they have in common with T.M.❤️ , and whether or not they show up in the top X% of the artist pool.
| other_name | num_playlists | top_5% | top_10% | top_25% | top_50% |
|---|---|---|---|---|---|
| Emotional Oranges | 5.0 | False | True | True | True |
| GoldLink | 5.0 | True | True | True | True |
| The Internet | 4.0 | False | True | True | True |
| PJ Morton | 3.0 | False | True | True | True |
| VanJess | 3.0 | True | True | True | True |
| CeeLo Green | 3.0 | True | True | True | True |
| Steve Lacy | 3.0 | True | True | True | True |
| YEBBA | 3.0 | False | True | True | True |
| Nao | 3.0 | False | False | True | True |
| Shay Lia | 3.0 | False | True | True | True |
Who we decide to recommend depends on the novelty that the user is looking for. We can avoid recommending well known artists by filtering out the top 5%, or maybe 10% of connected artists. From the above artists I can say that I know CeeLo Green from the radio, The Internet from my "cool" West Coast friends, and I‘m very familiar with GoldLink‘s "Herside Story," but that‘s about it.
Now I get to perform some biased user-testing on the remaining artists!
In future posts, I‘ll cover how to scale the recommender and best store recommended artists; as well as how to display recommendations interactively through the magic of web development.
Gustavo