Building an artist recommender — Part II
Check out part 1 if you haven't already…or don't; you do you.
Review
At this point, I have a working artist recommender. Sure, it may be based solely on the Spotify user’s playlists, is mostly undocumented, and can only be queried from a command line… but it’s mine.
Recall the stats of the current pool of playlists:- 1,469 playlists
- 30,300 artists
- 76,508 playlist to artist combinations
- 5,165,957 artist to artist connections (by way of playlists)
The recommendations are starting to make sense and I’ve discovered a few really good artists from it (shout out to Middle Kids and Aeris Roves). Still, I think the recommendations can be improved by increasing the size of the playlist dataset — thus getting a higher diversity of artists, and far more possible results.
Finding public playlists
Let me say from the start that Spotify has a pretty strict Developer Terms of Service, and I have to make sure that whatever I build complies with their rules. Overall, I need to minize the amount of data that I store (definitely no user or playlist data), and respect the single access token rule (i.e. not use any form of IP spoofing, or use other user's access tokens).
So far, it’s been pretty easy to extract playlists using the Playlist API, since I’ve known that I can search for either the Spotify user ID or my own. This gets a bit trickier when you don’t know other people’s IDs. Even after diligently reading Spotify’s API documentation, I couldn’t find anything about bulk search other people’s public playlists. Weird.
The easiest way around this is to look for a set of tokens with the Search API to find playlists — I searched for genres and months of the year. According to their documentation:
"Searching for playlists returns results where the query keyword(s) match any part of the playlist’s name or description. Only popular public playlists are returned."
Using this approach would get me more playlists, but it would still be limited to "popular" ones. Luckily, one of the data points that the Search API returns, is playlist owner's user ID. I can then use this to query all their public playlists, just like I was doing before. The only difference is that I'll be doing that for about 1.2M IDs instead of 1. Same difference.
I know what you're thinking… Searching for all public playlists is going to take a LONG time. You're right, to stay within the bounds of Developer Terms of Service, I wrote script that would stream the playlists with a single access token on a single GCP Compute Enginge. It stores the playlist ID that each artist shows up in using a sparse matrix. The script checks for sensical things like "has this user been processed before?", but the main limitation is set by Spotify's requests per second threshold.
So now I wait… and wait… and wait some more. After over a month of querying, I got the following results:
- 10,604,804 playlists
- 1,722,840 artists
- 358,935,838 playlist to artist combinations
Building an artist to artist graph
Next step is to build the artist to artist network graph. Turns out this problem becomes a tad more complicated with this number of artists. My current iterative approach of finding the number of playlists any two artists have in common won't cut it since it will blow out my machine’s memory too quickly.
The problem boils down to performing the following operation:
| playlist_id | artist_id |
|---|---|
| 123 | 1 |
| 123 | 2 |
| 456 | 1 |
| 456 | 2 |
And turn it into this:
| first artist | second artist | connections |
|---|---|---|
| 1 | 2 | 2 |
| 2 | 1 | 2 |
For a smaller dataset, doing an inner join on playlist_id, and later reducing the artist_id pairs would suffice.
For a larger dataset, this is incredibly inefficient. I’m knowingly expanding the size of the data frame to later collapse it. Knowing this was a bad idea, I tried it anyway!
- First, I tried it using Python + Pandas on my local machine. After hours of running, it crashed my computer.
- Second, I tried using Python + Dask to see if it was a Pandas issue. After hours of running, it crashed my computer.
- Third, I ported the same procedure to Spark, and ran it on Google Dataproc, using a healthy number of resources. The next morning I woke up to $150 charge to my account with no results…
Once that happened, I decided to take a break and spend time on other stuff, you know, maybe take a pottery class in Crown Heights or go kayaking through the Gowanus Canal.
After not working on it for a few weeks, the solution dawned on me during a glass blowing workshop in Park Slope or some other generic millenial activity, I forget. Clearly joins didn’t work, so I need to represent the input table in a different format. I noticed that the result could be represented by a sparse matrix of size [Number of artists] X [Number of artists], so it can be stored efficiently using a coordinate format matrix.
By thinking of the output as a matrix, there was a natural way to repsent the input — store a binary value indicating whether or not an artist (row) shows up in any given playlist (column):
| Artist/Playlist | 123 | 456 |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 1 | 1 |
I can find the number of playlists any two artists have in common by performing a dot product between the above matrix \(A\), and it’s transpose.
$$A\cdot{A^T}$$| Artist | 1 | 2 |
|---|---|---|
| 1 | 2 | 2 |
| 2 | 2 | 2 |
The diagonal represents the total number of playlists for a single artist. Here's a visualization showing the top 25 artists — hover over any cell to see the number of playlists any two artists have in common. At first the number of artists was set to 75, but the visualization was too big, and not to mention that Daddy Yankee is #75… and he's just the worst.
After spending hours of my life, and hundreds of dollars on failed solutions, I was able to solve the problem with less than an hour of processing time on a single machine using high school level math. Lesson learned.
Storing and Querying
Now that I’ve quantified the relationships between the 1.7M artists, I have to start thinking about how a front-end interface would query this. The whole point of this tool is to give the user more control over the type of recommendations they get. It has to be fast, and I want to limit the number of necessary queries. In order to limit having to query the Spotify API from the web app, I’ll need some metadata on the artists. For that, I queried the 1.7M artists using the Artist API to get their:
- Genres
- Image url
- Spotify url
- Popularity score
- Number of followers
I decided to store artist data using Firebase, and index the artists using their Spotify ID. For example, below is the record for Lana del Rey that contains all her metadata.
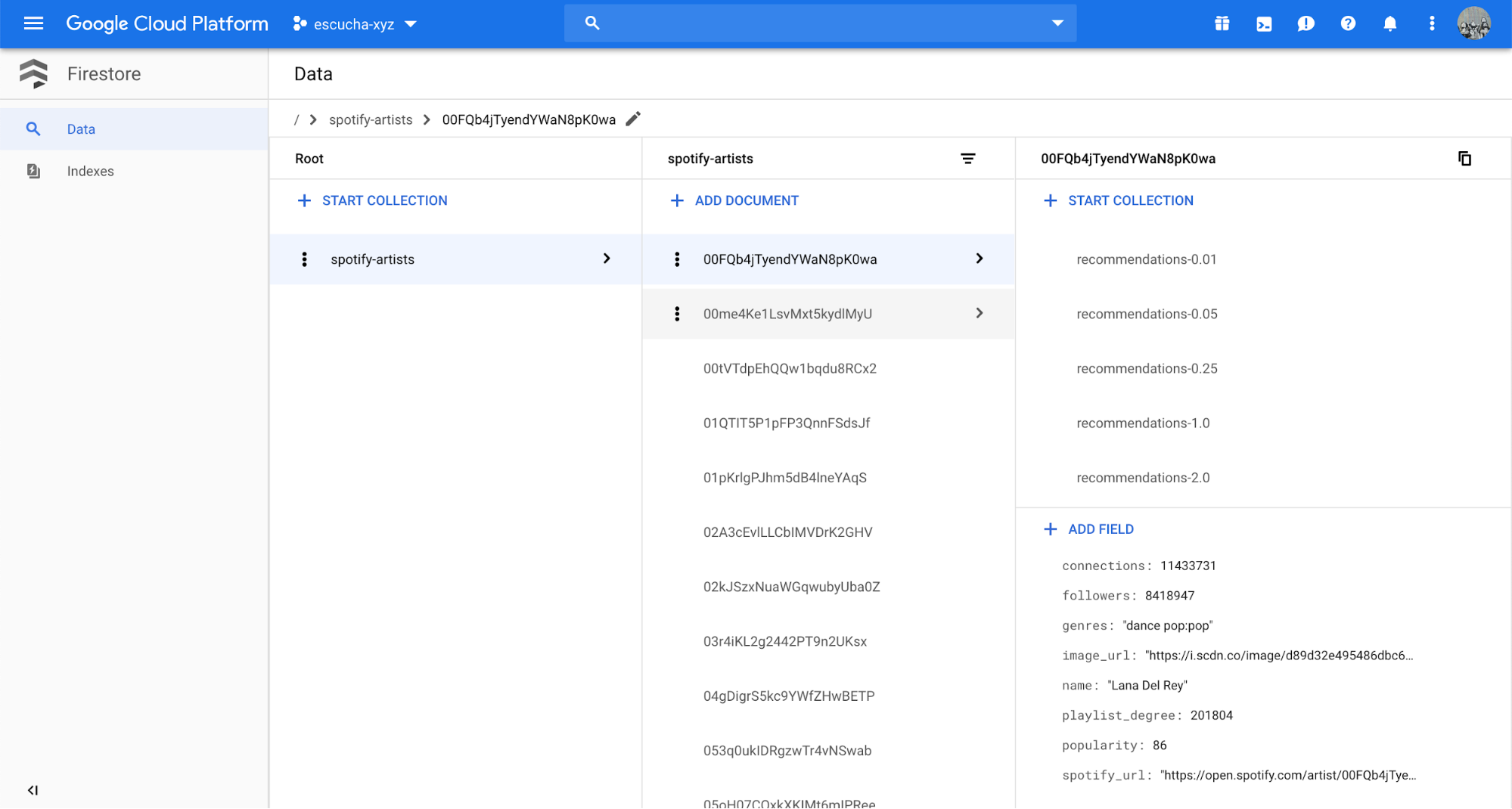
Most of the metadata comes directly from the Spotify API, the main addition from my dataset is the connections and playlists_degree fields. The playlist_degree tells me that Lana Del Rey shows up in 201,804 playlists in my sample of 10.6M playlists. The connections field tells me that in the pool of playlists that she's a part of, there was a total of 11,433,731 non unique artists.
I use the connections field to rank artists, and ultimately filter them from recommendations since I want to avoid recommending super well known artists.
Lana Del Rey has 5 sub-collections that each contain 100 recommended artists. Each sub-collection avoids a certain percentage of the "top" artists.
- recommendations-0.01 — filters out the top 0.01% of artists
- recommendations-0.05 — filters out the top 0.05% of artists
- recommendations-0.25 — filters out the top 0.25% of artists
- recommendations-1.00 — filters out the top 1.00% of artists
- recommendations-2.00 — filters out the top 2.00% of artists
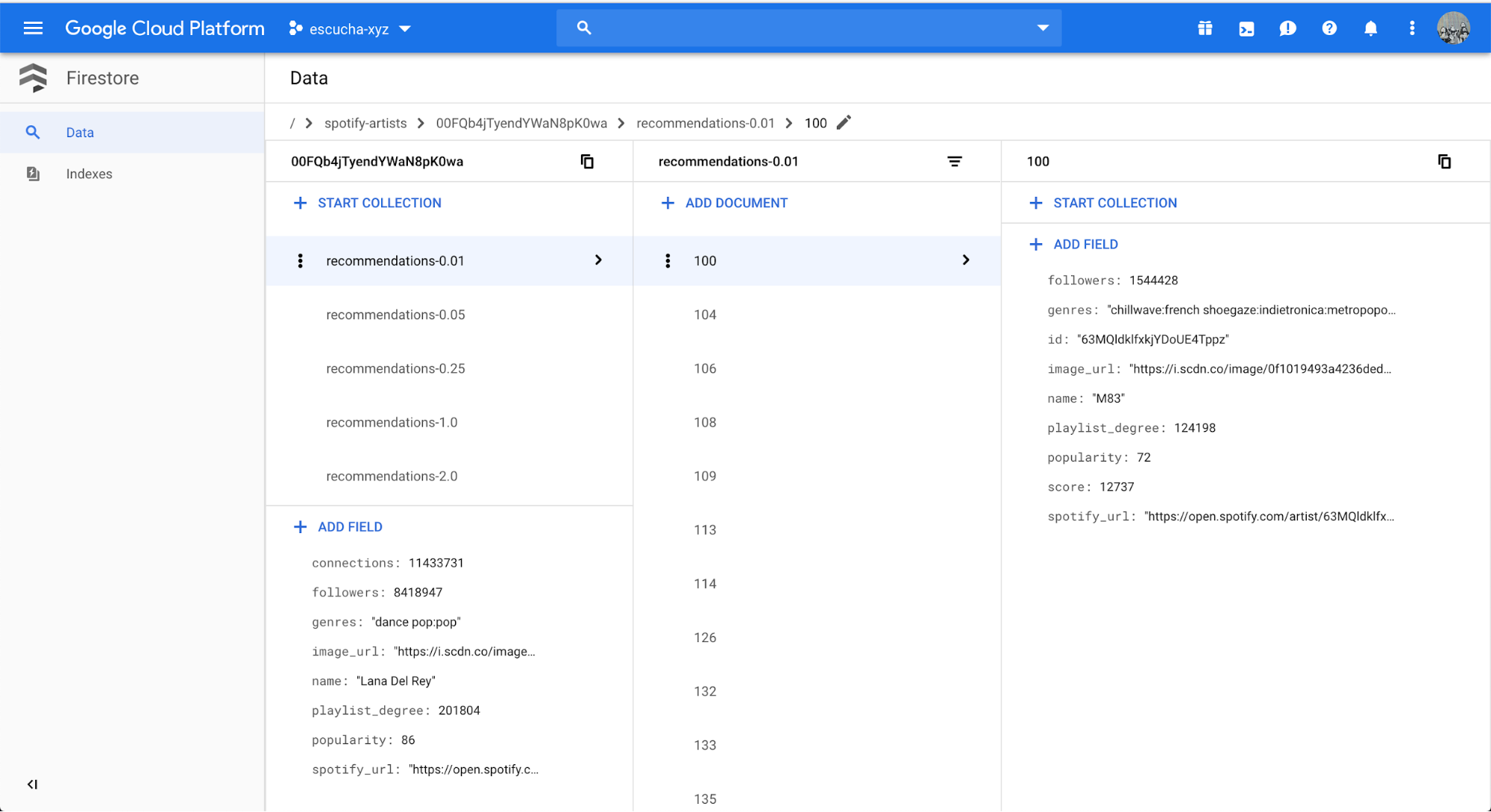
For example, M83 is the 100th artists that is most connected with Lana Del Rey, but the first 99 all fell within the top 0.01% of artists, so they were ignored. M83 has 12,737 playlists in common with Lana Del Rey, out of their 124,198 playlists. That seems a bit high, since that’s over 10% of the playlists they show up in — it wouldn’t surprise me if this is due to a remix or a collaboration they both show up in.
Now I need to determine how many artists I should actually store recommendations for — this is a reasearch project and I’m not trying to pay $50 / month in database fees. Since, a disproportionately small number of artists show up in most playlists, indicating our collective lack of imagination, I’ll only store recommendations for the top 750 artists. Which means that at most I’ll store 750 * 5 categories * 100 = 375K non-unique recommendations.
The Interface
Almost all the pieces are in place, except for the interface. I'm not a front end developer, so I spent some time reading different articles to see what tools the cool kids are using these days in web development land. I found a lot of talk of React.js, so I did a few tutorials, and learned how to use the main plugins to build my web app. There are so many open source packages for dropdown menus, and other components that made the process rather simple.
Go ahead and test it out. Hopefully you find an artist that surprises you.
Gustavo